
这个“湖”有什么不同?

作者 | 王嘉善
公司出品 | 学雷锋网产业组
当前,对每一个民营企业的网络化结构调整和可持续发展来说,统计数据起著了非常重要的作用。
所有人业务统计数据化,所有人统计大列佩季哈区化,也正式成为现今众多民营企业的笨蛋。
据著名咨询公司统计,到2025年亚洲地区统计数据总额将超过160ZB,亚洲地区统计数据总额的近 20% 将正式成为影响现实生活的关键性统计数据,近 10% 将转变成超关键性统计数据。
接踵而至的就是,民营企业对统计数据洞悉灵巧度要求的不断提升,同时民营企业也亟需可以利用多个统计管理工具、使用相同的大统计数据挖掘控制技术,快速构筑灵巧亲善的统计数据构架,解决多样化分析情景的统计数据市场需求。
如前所述这一洞悉,日前,百度云首次对外展现完备使用者端统计数据湖商品图表,并面世三款照相狸尾豆统计数据湖商品——统计数据湖排序服务DLC和统计数据湖构筑DLF。
云原生植物智能化统计数据湖到底具有了什么样潜能?可为民营企业增添什么样价值?为了深入探讨这些问题的标准答案,会前,学雷锋网与百度云大统计数据商品服务中心副总经理雷小保姆、百度云罐子商品总经理崔真、百度云AI应用商品服务中心总经理王东进行了一场谈话。
云原生植物智能化统计数据湖增添了什么样相同?
不可否认,统计数据湖并非是一个捷伊基本概念,早在2010年,Pentaho创办人兼CTO约翰·梅森(James Dixon)就提出统计数据湖基本概念,前两年Pentaho发布了开放源码架构的Hadoop第三版。
随后,红色勇士IBM、EMC等也面世了统计数据湖应用软件系统,其核心如前所述sysfs建立的统计数据储存方式,纵向扩充比较强悍,实现了依法治理管理。在此之后,如前所述HDFS系统增添的Hadoop和Spark开放源码自然生态构筑,也在一定程度上推进了民营企业统计数据湖的民主化。
但受制于开放源码应用软件本身潜能的限制,传统统计数据湖控制技术难以满足民营企业使用者在统计数据规模、储存成本、查阅操控性以及灵巧性排序构架升级换代等方面的市场需求,难以达到统计数据湖构架的平庸目标。

在雷小保姆看来,传统的统计数据湖商品只是解决了大统计数据存的问题,在用的维度上并没有产生更大的价值。
而伴随着网络化时代的到来,民营企业使用者对大统计数据商品有了更高的要求,需要更低廉的统计数据储存成本、更精细的统计数据资产管理、可共享的统计数据湖元统计数据、更实时的统计数据更新频率以及更强悍的统计数据接入工具。
这直接导致了传统统计数据湖商品难以深入民营企业级行业使用者。
面对着民营企业对大统计数据工具市场需求的全面变化,以及以云排序为服务中心、以统计数据驱动业务及可组合式统计数据构架正式成为数智时代的统计数据挖掘的趋势下,云原生植物智能化统计数据湖应势而生。
云原生植物智能化统计数据湖,能够很好的扩充排序和储存资源,同时能极大地降低运维管理难度,实现业务灵巧部署。同时可以助力各行各业解决多样化统计数据挖掘情景的新市场需求,更好地激发大统计数据在民营企业网络化升级换代过程中的价值。雷小保姆接着对学雷锋网表示到。
相比过去的统计数据湖,云原生植物统计数据湖的优势主要体现在能够以极低的价格共享储存服务;排序资源能够按需扩容,按量付费;同时随着统计数据湖全链路应用软件系统的不断完善和增强,也在打破统计数据孤岛、实现多样化统计数据挖掘等方面具有独特优势。
如前所述对行业的这一理解,在雷小保姆看来,民营企业需要一个具备端到端的云原生植物统计数据湖应用软件系统,从储存、排序到智能化的统计数据挖掘,再到偏向业务情景的各种统计数据应用,通过从下到上的把这些潜能聚合在一起,同时结合统计数据湖的潜能去解决业务中的具体问题,并能够快速搭建并运用统计数据湖的控制技术构架。
云原生植物智能化统计数据湖增添了什么样价值?
随着控制技术的不断演进,统计数据库控制技术正在与云排序以及人工智能化控制技术相融合,结合云排序以及人工智能化的特性,云统计数据库正呈现出更高的统计数据灵巧度、更优的统计数据储存分析成本,以及更极致的资源灵巧性潜能,在打破统计数据孤岛、实现多样化统计数据挖掘等方面具有独特优势。
就以百度云原生植物智能化统计数据湖为例,其商品矩阵包括统计数据湖储存、统计数据湖算力调度、统计数据湖大统计数据挖掘、统计数据湖AI潜能、以及统计数据湖应用和云上基础服务六个层面,提供一体化的全方位服务。
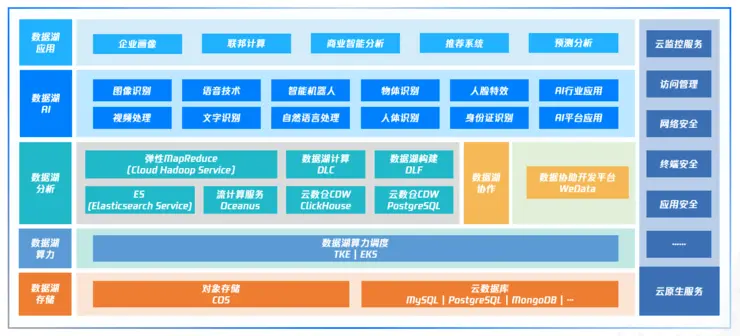
在储存方面,百度云原生植物统计数据湖储存以对象储存COS服务为核心,理论上可以储存任意规模的异构统计数据,具有高可靠性和高持久性,同时也支持将其他使用者端统计数据设施作为统计数据湖的储存服务。
对百度云对象储存,学雷锋网曾在《百度储存控制技术背后的十五年往事》一文中进行详细描写过,百度云对象储存COS如前所述新一代储存引擎YottaStore打造,不仅具有高可用、高操控性和低成本等优势,且在储存可靠性、开放兼容和统计数据安全方面也为海量统计数据的储存和管理提供了更强悍的支持。此外,百度云对象储存COS还进一步通过三级加速器,提供储存端元统计数据、近排序端统计数据缓存以及AZ级全闪存硬件加速潜能,可以满足使用者低成本、高操控性、流批一体地挖掘统计数据资产价值的市场需求。
在算力调度方面,百度云灵巧性罐子服务EKS,具备存算分离、缓存加速、灵巧性排序潜能,既能帮助民营企业充分利用云上资源的灵巧性潜能,极大减少集群空闲时期的成本浪费,也能快速、安全的提供多样的算力资源。
据崔真介绍,灵巧性罐子服务EKS不仅经历了三次大的控制技术构架重构,同时也在百度云几十万、几百万台的物理机上做了部署,实践验证了其高可用和稳定性,它既可以提供一个运维简单、兼容原生植物Kubernetes的Serverless罐子平台,也能更快更灵巧性更安全且无需对集群管理实现管理,同时更具备跨可用区的容灾,罐子沙箱及热迁移等高级功能,真正实现了极致的资源使用灵巧性。
同时,面向民营企业的混合云部署情景,百度云的EKS可以在使用者的机房中部署一个插件,当客户需要更多算力资源的时候,通过这一个插件就可以使用百度云提供的性罐子服务EKS服务。
其次,在统计数据湖分析方面,百度云原生植物统计数据湖同样既提供半托管的泛Hadoop服务,满足使用者自定义市场需求,也提供全托管的统计数据服务,便于使用者获取海量统计数据的洞悉力。同时,使用者还可利用百度云提供的统计数据协作工具对排序服务进行编排和调用,大幅度提升民营企业统计数据的便捷性和灵巧度。
在统计数据湖智能化应用方面应用方面,百度云面世了如前所述统计数据湖的统计数据应用服务,如民营企业画像、联邦排序、商业智能化分析等。同时,百度云统计数据湖更包含了丰富的AI服务,能够为图像处理、音频处理、自然语言处理、视频处理等提供有力的统计数据支撑。
据王东介绍,云原生植物统计数据湖为AI的应用提供了统一的统计数据构架,在统计数据收集、标注、训练、推理等领域都能够发挥更大的作用,而百度云凭借亚洲地区领先的控制技术和创新方案,打造了领先的统计数据湖与AI融合平台,为更多的应用情景提供了智能化化的潜能。
以百度云内容安全智能化服务为例,该服务如前所述云原生植物统计数据湖构架,以AI智能化审核潜能为核心,从接口输入、辅助判断、模型识别、客户策略处理以及人工审核与平台六大维度,为使用者提供了完备的内容安全应用软件系统,让客户一次调用即可完成所有的内容审核工作。在此基础上,百度云也不断通过统计数据湖结合AI的潜能赋能客户,在科技战疫、OCR识别、智能化票财税等应用情景领域发挥了更多的价值和作用。
为民营企业释放统计数据价值
当满足了使用者对大统计数据商品市场需求之后,对商品提供者来说,如何让使用者快速的用上该商品则正式成为了下一个问题。
为了让使用者更快的建立起统计数据湖环境,百度云原生植物智能化统计数据湖还打造了三款全捷伊照相狸尾豆统计数据湖商品——统计数据湖排序服务(Data Lake Compute,简称:DLC)和统计数据湖构筑DLF(Data Lake Formation,简称:DLF)。
其中,统计数据湖排序服务DLC服务采用无服务器构架(Serverless)设计,使用者无需关注底层构架或维护排序资源,使用标准SQL即可完成对象储存服务(COS)及其他使用者端统计数据设施的联合分析排序。借助该服务,使用者无需进行传统的统计数据分层建模,大幅缩减了海量统计数据挖掘的准备时间,有效提升了民营企业统计数据灵巧度。
不仅如此,百度云统计数据湖构筑DLF则提供了统计数据湖的快速构筑,以及与湖上元统计数据管理服务,能够帮助使用者快速高效的构筑民营企业统计数据湖控制技术构架,包括统一元统计数据管理、多源统计数据入湖、任务编排、权限管理等统计数据湖构筑工具,借助统计数据湖构筑,使用者可以极大的提高统计数据入湖准备的效率,方便的管理散落各处的孤岛统计数据。
值得注意的是,DLF不仅可以兼容百度商品产生的异构统计数据,它也可以兼容百度云之外的异构统计数据。
统计数据显示,如前所述这三款统计数据湖商品,相比于本地自建大统计数据集群,统计数据湖构筑时间减少了60%,统计数据挖掘排序操控性提升35.5%,使用者端统计数据湖构架投入使用后可使存算统计数据量增长75%,配合其他大统计数据服务,在业务峰值期可以节约30%的硬件资源,以及一半的大统计数据工程师和运维工程师。
如何保证统计数据湖的稳定性
对任何大统计数据商品而言,其稳定性的重要性是不言而喻的。
对此雷小保姆对学雷锋网表示,百度云此次发布的百度云原生植物统计数据湖商品在内部经历过长期实践和锤炼之后才对外发布的。
以百度新闻为例,百度新闻拥有千亿级的文章数量,每篇文章各环节统计数据维度达到几百个,多维度的统计数据主题导致各个业务环节的统计数据量线性膨胀,也这给统计数据挖掘带了极大的挑战。
为此,如前所述百度云原生植物统计数据湖控制技术构架,在统计数据采集、统计数据储存、统计数据挖掘的全统计数据链条上提供了高可靠高可用的灵巧性统计数据潜能。目前已接入全量文章的索引统计数据,文章索引达日均30-50亿/100G+ ,支持准实时写入更新,业务统计数据链路延迟提升至分钟级别,使得算力资源节约超过50%,综合运行成本降低了30%,大统计数据运维工程师的工作量提升了100%。
百度新闻的统计数据应用中,既有偏离线的,也有偏实时的,更有偏批量和小部分统计数据查阅的,情景十分的多样化,而百度云如前所述多样化的应用情景,不断对云原生植物统计数据湖方案进行孵化和打磨,最终让百度云原生植物统计数据湖应势而生。
除此之外,百度云正在积极推动统计数据湖在政务、工业、零售等领域的大规模落地。
目前,百度云统计数据湖体系已服务众多内外部客户,其整体算力灵巧性资源池已达500万核,储存统计数据超过100PB,每日分析任务数达1500万,每日实时排序次数超过万亿,能支持上亿维度的统计数据训练。
显然,作为数智时代的统计数据处理的新引擎,云原生植物智能化统计数据湖能够为使用者增添更多的可能性。


相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~