
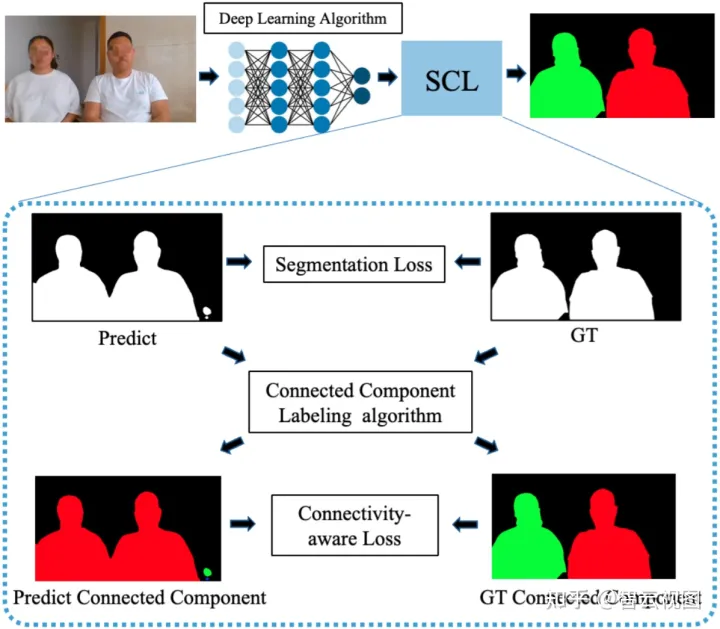
PP-HumanSeg用大数据集+连通性loss实现视频会议下的高效人像分割
【序言】
圣诞节写的首篇该文,给我们写呵呵腾讯的paddlepaddle裂瓜WACV2022W上的人像拆分的组织工作。
下列阐释与看法均为我的对个人认知,就算我有这儿歪曲了,造成了无谓的麻烦事,能联络我删掉该文,也能在该文区回帖,我展开修正。也热烈欢迎我们在该文区展开沟通交流,就算有甚么有趣的paper也能回帖,我抽时间看呵呵也能写许多。节录文本中的译者两字词,均是指paper的译者,我的对个人看法会隐式的我标明。而该文的图基本上都从paper上cv回来的,我也何必如此重做那么多的图,更何况译者的图弄得还没关系看的。
Paper基本上重要信息
试题:PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
译者:Lutao Chu, Yi Liu, Zewu Wu, Shiyu Tang, Guowei Chen, Yuying Hao Juncai Peng, Zhiliang Yu, Zeyu Chen, Baohua Lai, Haoyi Xiong
镜像:
Github:
归纳:明确提出了两个小规模的宗乡卡人像拆分统计数据集并如前所述此结构设计了两个如前所述人像封闭性的loss来提高宗乡卡嘉犁像拆分的操控性
Paper文本如是说
【基本上如是说】
人像拆分的商业用途是很广的,有交互式大背景、美化滤镜、人物特效等等,而这篇该文主要关注的是视频交互式大背景需求下的肖像拆分问题。宗乡卡交互式大背景的肖像拆分的难点,主要就在于设备和平台的多样性,设备上有可能是PC,也有可能是手机;平台上有腾讯会议这类的客户端形式的,又会有Google Meeting这类如前所述浏览器形式的。就我对个人而言,我在PC上用过腾讯会议和Google Meeting的交互式大背景,他们两个计算负载都很轻,压力不大,但是确实腾讯会议的抠图效果看起来是要比Google Meeting的好一点。
前段时间我们也写过并放出来了两个简单的人像抠图的模型:智云视图:人像抠图
目前人像抠图用的几个统计数据集主要有:
EG1800:1800张来自Flickr的图AiSeg:34427张来自Flickr、腾讯、淘宝的图FVS:10个视频共3600帧图像Maadaa:大约10万张的图译者这里就认为,这些抠图统计数据集虽然是挺大的,其中也有部分的宗乡卡统计数据集,但都质量不行,还得是自己弄个统计数据集。所以译者们明确提出了两个包含23个不同场景,有291个会议视频共有14117个标注图像的大型视频人像统计数据集,同时明确提出了一种自监督的连接感知学习方法,并如前所述此结构设计了两个轻量级的网络。该组织工作的主要贡献为:
公开了两个统计数据集(要发邮件给paddleseg@baidu.com问他们要的喔,不是随便就能下载的)明确提出了一种新的自监督连接感知学习(SCL)方法,从封闭性的监督提高拆分操控性明确提出了两个超轻量化模型,同时实现了操控性和推理速度之间的最佳平衡【相关组织工作】
统计数据集(前面写过了,这里不赘述)学习方法和轻量化模型语义拆分常用的loss:交叉熵loss、lovasz loss、dice loss、RMI loss等常用改进方法:多分支网络【统计数据集】
统计数据收集统计数据特征场景多样性,包括会议室、办公室、公共办公区、客厅、教室等动作多样性:挥手(这个在Google Meeting上问题很大)、起身、坐下、喝水、玩手机、握手等其它:大量戴了口罩的统计数据统计数据量23个场景,291个视频,分辨率1280×720,用2.5fps抽帧得到14117张高清图像统计数据标注逐像素标注肖像拆分有两个不确定情况:手持物品和远处的人考虑到应用的是宗乡卡场景,手持的物品与会议强相关,所以要标注到一起,而远处的人能认为是无关的,则不标注视频级别标注视频片段的属性:场景id、参与者数量、参与者活动、戴口罩、过路人等这些属操控性用于视频描述、多任务学习、人类活动分析等统计数据合成额外收集了90个不同宗乡卡场景的纯大背景图像,能通过视频合成来扩充统计数据集译者们最后做出来的统计数据量能到大约100万张图像(大力出奇迹)【SCL方法】
A. 语义封闭性
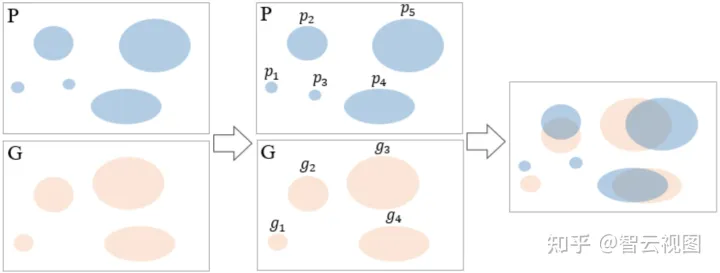
译者将两对个人的示例区域看作是两个连接组件,上图是连接组件计算和匹配的两个示意图,P是预测结果,G是Ground Truth。译者这里用鲁棒性较好的CCL算法来计算连接组件,然后遍历G和P的所有连接组件来找到所有相互相交的组件对,上面的示意图中就有三对[g2,p2][g_2,p_2]、[g3,p5][g_3,p_5]、[g4,p4][g_4,p_4],以及三个孤立组件p1p_1、p3p_3和g1g_1。假设gig_i与{p1,p2,⋯,pk}\{ p_1,p_2,\cdots,p_k \}成对,那么gig_i的封闭性CiC_i能计算为:
Ci(P)=1k∑k=1kIoU(gi,pk)∈(0,1]IoU(gi,pk)=|gi∩pk||gi∩pk|\\ C_i(P)=\frac{1}{k}\sum^k_{k=1}IoU(g_i,p_k)\in(0,1] \\ IoU(g_i,p_k)=\frac{|g_i\cap p_k|}{|g_i\cap p_k|}
那么最后整个图的语义封闭性SC能计算为:SC(P,G)=1N∑i=1NCi(P)\\ SC(P,G)=\frac{1}{N}\sum^N_{i=1}C_i(P)
B. SC loss
SC loss的目标是要最小化预测和GT之间的语义封闭性不一致,而当预测结果与GT没有交集的时候用如前所述面积的loss来优化模型。
P和G之间至少有一对连通时:LSC(P,G)=1−SC(P,G)L_{SC}(P,G)=1-SC(P,G)P和G之间不存在连通对时:这种一般出现在训练开始的时候,SCL中零封闭性会导致梯度为0,所以要用别的loss来做模型训练的冷启动:LSC=|P∪G||I|L_{SC}=\frac{|P\cup G|}{|I|}最终的总loss只要在一般的拆分loss的基础上把SC loss也加上就完事了。
【ConnectNet网络】
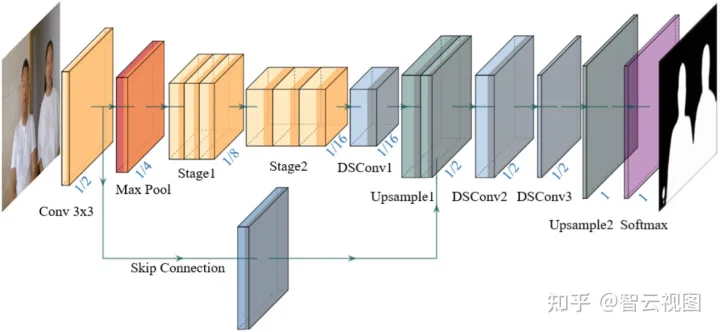
网络这个没甚么好写的,看许多图就完事了,真要看细节还得是去看代码。
【实验】
这个组织工作看起来还挺便宜的,译者就用了两张V100来跑。下面我们简单看下效果图:

不知道是我看的不仔细还是啥的,译者他们搞了那么个所谓的超轻量化网络,居然没有给网络的推理时间。


相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~